The Missing Layer: Why Persistent AI Agents Need a Semantic Persistence Engine
Inside the memory architecture powering my 24/7 autonomous agent, and why you might be building yours wrong

Over my past two weekends, a cumulative 48+ hours went into debugging my persistent AI agent’s scheduled jobs, which kept silently failing. Turned out one configuration file was quietly overriding another. The agent had the wrong credentials without knowing it. It was running. It looked healthy. It was sending requests and getting back nothing. No error. No crash. Just silence.
That’s the kind of problem nobody mentions in the “build an AI agent in 10 minutes” tutorials. And it’s the kind of problem that only matters when you’re running an enhanced agent in production. Not for a demo, not for a blog post, but actually running it 24/7, digesting content and information through different channels: email, industry digests, stock monitors, and web research. Delivering to real people on Telegram and WhatsApp. I’ve been running my AI agent for the past weeks (nearly) 24/7 in production and will share with you my findings and insights.
The Problem With Stateless Agents
Most AI agents in production today are stateless. They receive a prompt, generate a response, and forget. Every session starts from zero. The industry has spent three years in “Pilot Purgatory”: building RAG demos that work in the lab and crumble under real-world enterprise entropy.
The root cause isn’t the model. McKinsey’s QuantumBlack team published research confirming what practitioners already know: Gen AI applications fail because of unstructured data quality problems upstream. Format diversity, metadata gaps, version conflicts, and content noise. Adding chunk-level metadata tagging alone improved RAG accuracy by 20% in their study.
The model is the easy part. The execution is harder. And even harder is the part of giving the AI something worth remembering.
Systems of Record vs Systems of Action
Something broke in the last two years.
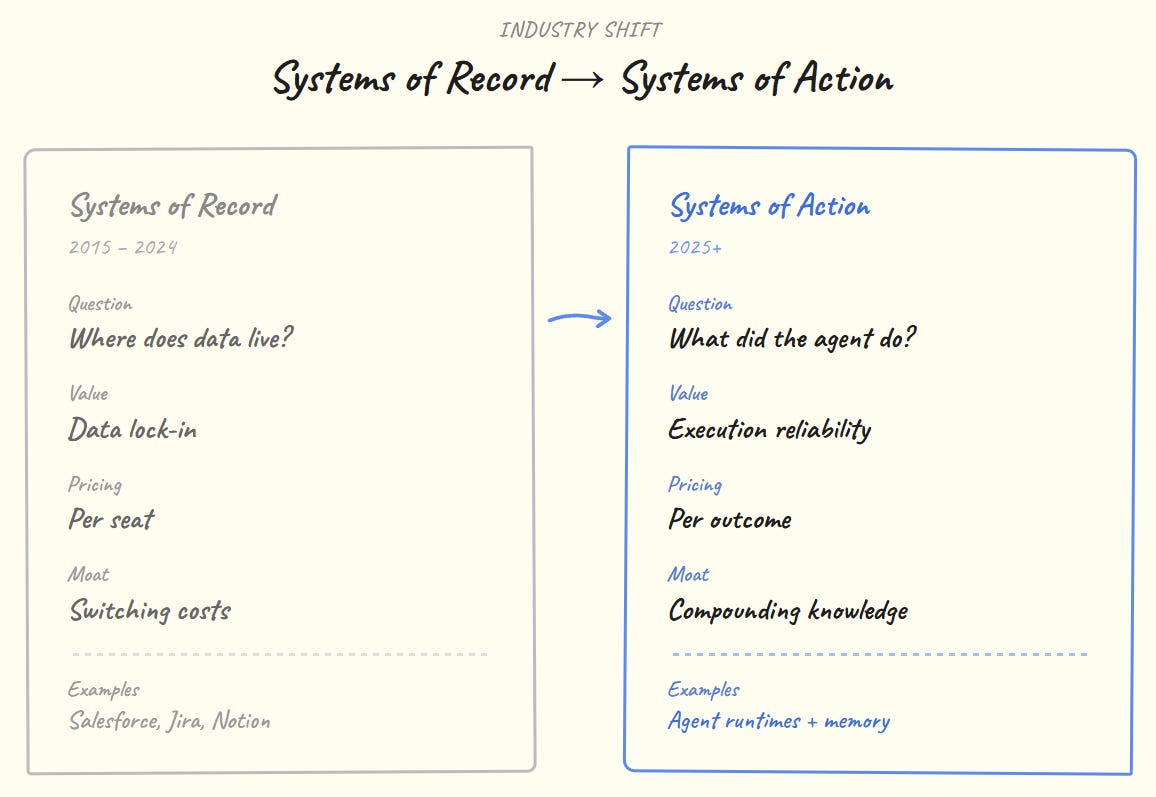
The market sizing tells the story: AI agents at $7.84B in 2025, projected $52.6B by 2030. That money isn’t for dashboards. It’s for agents that actually execute: process bookings, complete workflows, and make decisions. Salesforce is building Agent Force. Vercel is a shipping agent infrastructure. OpenAI hired the MCP protocol creator. They’re all converging on the same architecture.
But execution without memory is just expensive coin-flipping.
The Palantir Ontology Pattern (And Why It Matters Here)
The core idea comes from Palantir. Not the software, the design pattern.
Palantir’s Ontology is a semantic layer that maps real-world objects (people, organisations, events, transactions) into typed entities with explicit relationships. It sits between raw data and applications. Analysts don’t query tables; they traverse a graph of interconnected objects that mirror the real world. When a CIA analyst needed to find hidden connections between entities, the Ontology was what made that traversal possible. Not a search index. Not a keyword match. A typed, interlinked graph with enforced schema.
The critical insight: the Ontology is both human-readable and machine-actionable. An analyst can navigate it visually. A software agent can traverse it programmatically. Same artefact, two interfaces.
This design principle drives the memory layer of a persistent AI agent. Not a vector database. Not a chat log. A typed knowledge graph where every record carries structured metadata, explicit entity types, and bidirectional links. Exactly like Palantir’s Foundry Ontology, but implemented in Markdown with YAML frontmatter.

The difference: Palantir’s Ontology requires Foundry, a team, and a seven-figure contract. This one runs on a $10/month VPS and builds itself from raw inputs.
The 4-Layer Semantic Stack
Through production iteration, the system evolved into a 4-layer architecture where each layer is independent but interdependent. Remove one and the system loses its agency.

Most “AI agent” products only build Layer 3, the execution runtime. They route prompts to models and return responses. Without Layer 2, the semantic layer, they’re stateless. Without Layer 1, they’re reasoning over noise. Without Layer 4, they’re unaccountable.
The semantic layer is what converts a chatbot into an agent with institutional memory.
Three Memory Systems, Three Purposes
The semantic layer isn’t one monolithic store. My AI Agent splits into three distinct systems, each serving a different temporal and cognitive function:
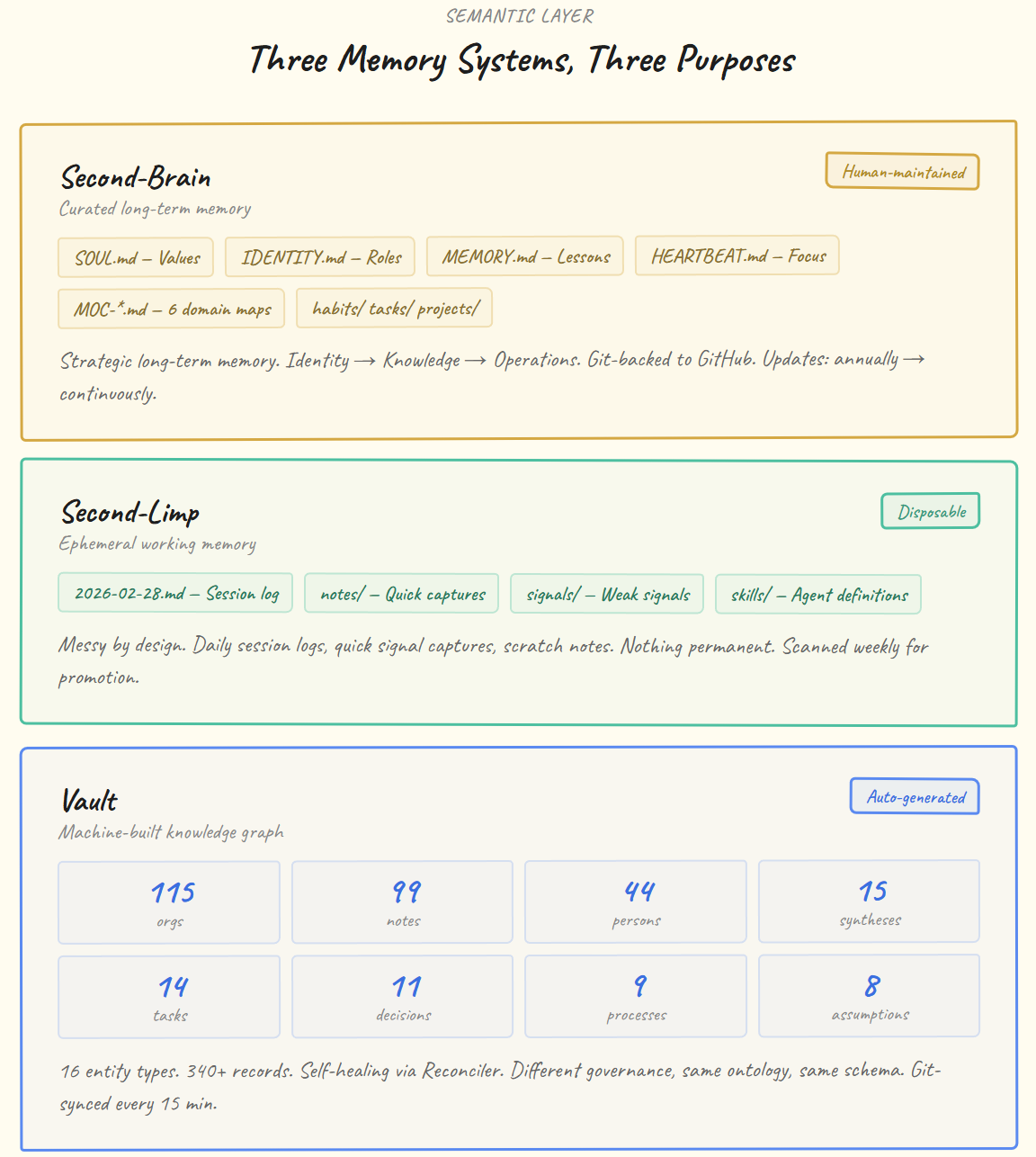
Why three systems instead of one?
Because anyone running a persistent agent lives three different temporal lives.
My second-brain is my strategic long-term memory. It has my Identity Layer that rarely changes: files that define values, boundaries, and roles (VP Data & Analytics, retail investor, angel investor, continuous learner). These get reviewed regularly. Below that sits a Knowledge Layer with six domain maps that organise everything across work, life, finance, portfolio, research, and systems architecture. There’s a file for evergreen lessons and decisions. A scratchpad that acts as session RAM. A heartbeat file, the agent checks every 30 minutes to know what’s in focus this week. At the bottom, the Operations Layer holds the actionable stuff: habits, tasks, projects, notes, finance records, each with typed frontmatter linking back up to the knowledge layer.
On my Sunday portfolio review, the map shows how an investment thesis connects to tracked projects and past decisions. When the agent reads the heartbeat file at 07:00 CET, it knows the current priorities and adjusts its behaviour. The second-brain is the stable semantic foundation. It tells the agent who the operator is, what matters, and how the world is organised.
My second-limp is the opposite. Messy by design. Daily session logs, quick signal captures, scratch notes, skill definitions like a writing-voice prompt used for content. Nothing here is meant to be permanent. Every week it gets scanned for items worth promoting. A signal that proved real gets moved to the second-brain. A scratch note that became a decision gets formalised. Everything else decays. This is episodic memory that prevents my second-brain from getting cluttered with half-formed thoughts.
My vault is where the machine operates. The Semantic Persistence Engine (SPE) workers build it automatically from every input the agent processes. It’s the complement to the human-maintained stores. My second-brain is curated with my judgment; the SPE builds the vault with its extraction pipelines. Different governance, same ontology, same schema.
This split matters because multiple roles (data leadership, venture building, personal investing, running an AI agent system) have different information cadences. My identity as an investor doesn’t change week to week. That’s my second-brain’s Identity Layer. But the stock monitors that fire daily and the content digests that arrive through email, research feeds, and personal correspondence generate raw signal that needs to be captured fast and processed later. That’s the second-limp feeding into the vault. The SPE takes that raw signal and builds structured knowledge: this company is connected to that person, this assumption underlies that decision, this constraint limits that project.
Without the second-brain, my agent has no sense of who it’s working for. Without the second-limp, ephemeral signals get lost. Without the vault, my agent can’t build on its own experience. They’re complementary layers of a single operating semantic, formalised into something an agent can use.
The Semantic Persistence Engine: Worker Pipeline
The SPE is built on Alfred, a knowledge management framework created by David Szabo-Stuban. Alfred provides four autonomous daemon workers (Curator, Janitor, Distiller, and Surveyor) that continuously build and maintain a typed knowledge graph.
Throughout this article, the workers are referred to as Harvester, Reconciler, Synthesizer, and Cartographer because I find those names better describe what each worker actually does in the pipeline, which makes the architecture easier to reason about. But the engineering and the original design are David’s, and the names in the codebase are his.
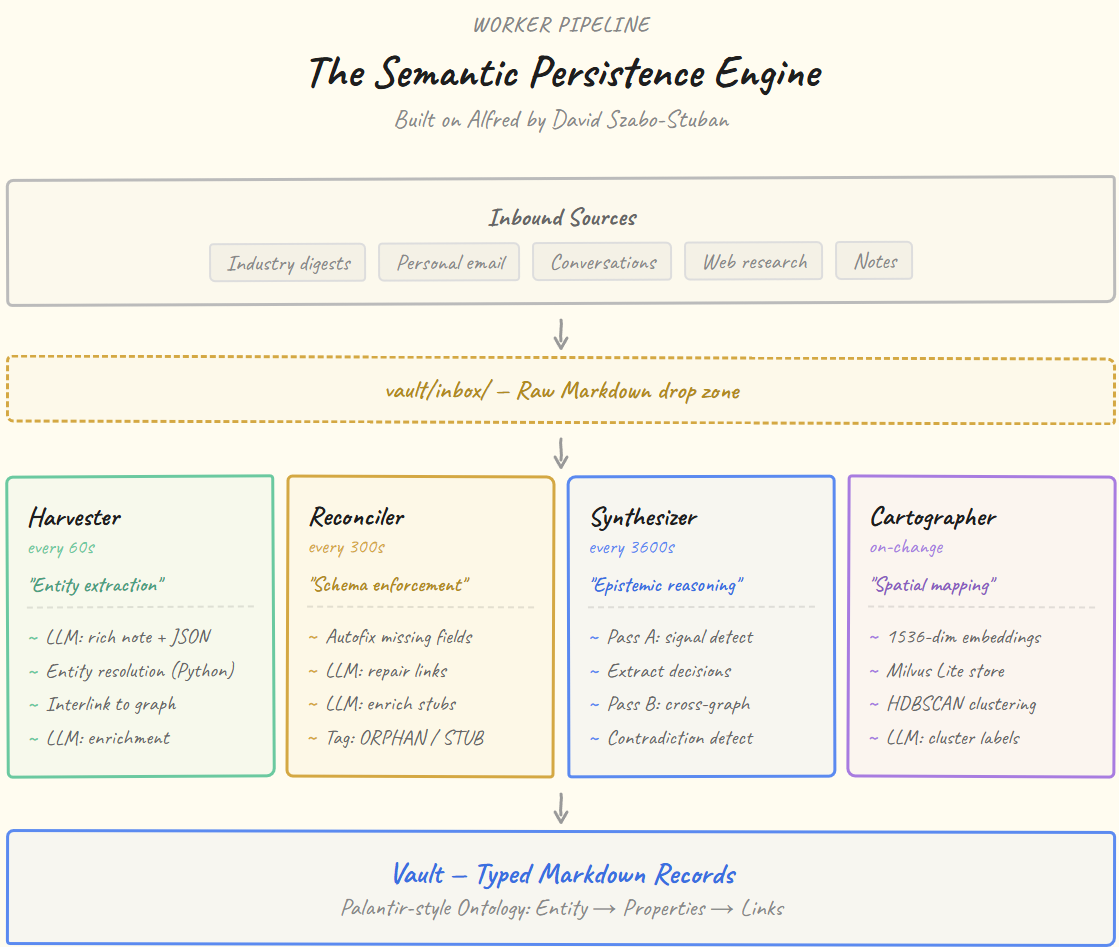
Each worker operates on a different timescale and a different abstraction level:
Harvester (60s). The fast path. Drops raw Markdown into the vault as typed entity records. Runs a 4-stage pipeline: LLM extraction, entity resolution against existing vault records (pure Python, no LLM needed for matching), interlinking, then per-entity enrichment. One input (a digest, an email thread, a research drop) becomes 10+ records in under a minute.
Reconciler (300s). The schema enforcer. Analogous to Palantir’s Ontology Management layer. Scans the entire vault for structural issues: missing YAML fields, broken [[wiki-links]], orphaned records with no inbound references (ORPHAN001), stubs that need content (STUB001). Fixes deterministic issues in pure Python, uses LLM only for link repair and stub enrichment. This is what makes the graph self-healing.
Synthesizer (3600s). The reasoning engine. Operates in two passes. Pass A scans individual records for epistemic signals (words like “decided”, “assumed”, “constraint”) and extracts them into dedicated record types (decisions, assumptions, constraints). Pass B runs meta-analysis across the entire reasoning graph: finding contradictions between decisions, surfacing shared assumptions, and generating emergent insights. This is what turns fact accumulation into a reasoning graph.
Cartographer (on-change). The spatial mapper. Creates 1536-dimensional vector embeddings via an LLM (e.g. local Ollama, stores them in Milvus Lite, then runs HDBSCAN clustering with Leiden community detection to find semantic neighbourhoods in the vault. Labels each cluster via LLM. This is what enables “find me everything related to X” without keyword matching.
The Vault Record Schema (Ontology in Practice)
Every vault record follows the Palantir Ontology pattern: a typed entity with structured properties and explicit graph edges.
yaml
# ──── EXAMPLE: Organization Record ────────────────────────────
---
type: org # ◄ Entity type (1 of 16)
name: Palantir Technologies # ◄ Object name
created: '2026-02-28' # ◄ Ingestion date
status: active # ◄ Lifecycle state
org_type: vendor # ◄ Type-specific property
website: https://www.palantir.com
description: >
Data analytics company, hybrid
software + consulting model
alfred_tags: # ◄ Cartographer cluster tags
- business-models/software-consulting
- case-studies/palantir
related: # ◄ Graph edges (Ontology links)
- '[[person/Peter Thiel]]'
- '[[person/Alex Karp]]'
- '[[org/In-Q-Tel]]'
- '[[synthesis/Software Plus Consulting...]]'
- '[[note/Palantir Origin Playbook...]]'
---
# Palantir Technologies
Human-readable content...yaml
# ──── EXAMPLE: Synthesis Record (Epistemic) ───────────────────
---
type: synthesis # ◄ Synthesizer-generated
name: Software + Consulting Hybrid Model as AI Go-to-Market Pattern
confidence: medium # ◄ Epistemic certainty
cluster_sources: # ◄ What the insight was derived from
- '[[org/Palantir Technologies]]'
- '[[note/Palantir Origin Playbook...]]'
related:
- '[[person/Peter Thiel]]'
- '[[person/Alex Karp]]'
---
# Software + Consulting Hybrid Model...
## Insight
Palantir's trajectory demonstrates that pairing software with
intensive on-site engineering can be a deliberate strategy...
## Evidence
- Alpha customer co-development (CIA, 2005-2008)...
## Implications
- AI companies should embrace the hybrid model...The 16 entity types form a complete ontology:

This is the Palantir Ontology pattern, implemented in flat files. Entity types map to Foundry’s Object Types. The related field maps to Foundry’s Link Types. The YAML frontmatter maps to Foundry’s Properties. The Reconciler maps to Foundry’s Ontology Management. Same pattern, zero infrastructure cost.
What One Input Produces
Concrete output from a single content file dropped into vault/inbox/:

That’s the difference between “storing content” and “understanding content.” The system doesn’t save text. It decomposes it into people, organisations, decisions, assumptions, and constraints, then connects them to everything it already knows.
What Actually Went Wrong (Two Weekends)
This took two full weekends of debugging. The architecture diagrams above are clean. The road to get there was not.
Weekend 1: one config file silently overrode another. The agent had the wrong credentials and produced empty results with no error message. Then a command-line tool needed its parameters in a specific order. Reverse them, and you get zero results, again with no error. Then the AI model name had to be written in one exact format. Spell it slightly differently, and the system fails over to a backup that also fails silently. Three bugs, zero error messages.
Weekend 2: a single typo in a dependency’s source code blocked the entire pipeline. One-line fix, but impossible to find without reading the library internals. Three of the four workers launch AI subprocesses. Turns out you can’t run the AI tool from inside itself, so the whole system hung on startup. Fix: run it as a background service instead. And the file permissions between two systems only worked because their internal user IDs happened to match by accident. Saturday evening, the content processing job died mid-run after consuming significant resources. Gone. No way to resume.
Every one of these is a boring, unglamorous infrastructure problem. None of them shows up in architecture diagrams. All of them are why most AI agents work in demos and break in production.
The Full Stack: How It Fits Together

The critical design choices:
1. Filesystem as IPC. The agent runtime and the memory system share the same filesystem but operate independently. OpenClaw writes to vault/inbox/. The SPE reads from vault/inbox/, processes, and writes to vault/. OpenClaw reads from vault/ when it needs context. Neither blocks the other. They communicate through the filesystem. The oldest, most reliable IPC mechanism there is.
2. Three memory cadences. My second-brain stores what I am researching and know (updated manually, reviewed weekly/monthly). My second-limp stores what happened today (ephemeral, disposable, promoted on review). The vault stores what the machine extracted (automatic, continuous, self-healing). Mixing these temporal cadences into one store creates the metadata chaos that kills agent reliability.
3. Ontology convergence. All three systems share the same schema primitives: YAML frontmatter, wiki-links, entity types. The second-brain uses id: PROJ-second-brain-setup, type: project, status: done. The vault uses type: org, status: active, related: [[person/X]]. Same ontology pattern, different governance models. This means my agent can traverse across all three stores using the same traversal logic.
The Data Flow That Compounds
Here’s a small example of what happens on my system for content consumption:

This is the compounding loop. Every day makes the vault smarter. Every vault record improves future agent responses. The agent isn’t answering questions. It’s building my digital twin of institutional knowledge that persists across sessions, restarts, and model swaps.
Why This Architecture Works
Three properties make this system reliable in production:
1. Temporal separation of concerns
The Harvester (60s) handles fast ingestion. The Reconciler (300s) handles maintenance. The Synthesizer (3600s) handles deep analysis. The Cartographer runs after content stabilises. No worker blocks another. If one fails, the others keep operating. Same principle as Palantir’s pipeline architecture. Each stage is independently deployable and recoverable.
2. The vault is the contract
There’s no internal API between the agent runtime and the memory system. The contract is the filesystem and the Markdown schema. Swap the agent runtime (OpenClaw to anything else) without touching the memory system. Swap the SPE implementation without touching the agent. The vault directory is the integration point. This is how Palantir’s Ontology works too. Applications bind to the Ontology, not to each other.
3. Human-readable by design
Every record is Markdown that opens in any text editor. The knowledge graph is navigable by humans using [[wiki-links]]. No special tool is needed to audit what the system has learned. git log shows exactly what changed and when. The second-brain and the vault share the same format. This isn’t convenience. It’s a trust mechanism. If you can’t read the agent’s memory, you can’t verify it. And if you can’t verify it, you can’t trust it.
Where This Is Going
Vercel is shipping agent infrastructure. OpenAI hired the MCP protocol creator. Salesforce is building Agent Force. They’re all converging on the same problem: how do you make agents that maintain state and execute reliably?
Palantir answered a version of this question fifteen years ago. Put a typed Ontology between raw data and applications. Let humans and software traverse the same graph. Enforce the schema automatically.
That pattern works for AI agents too. The models are commoditising. What isn’t commoditising is the memory layer that makes them persistent, reliable, and actually useful over weeks and months instead of single sessions.
The system processed its first input on a Friday. Just feeding it a few samples until Sunday, the vault had 340+ interlinked records across 16 entity types, built entirely from automated pipelines. Digesting content from email, industry digests, web research, and personal correspondence. Every new input makes the graph denser. Every denser graph makes the agent’s responses better. The config bugs, the silent failures, the permission mismatches: those problems are solved once. The compounding never stops.
Figure: Graph of my second-brain and knowledge DB (my semantics)
If your agent can’t remember what it did yesterday, it’s not an agent. It’s an expensive stateless function.
The 'expensive stateless function' framing nails it. This is exactly the failure mode that kills production agents - not the model, but the missing memory infrastructure. One thing I found building nightshift runs (agents working 10pm-5am unsupervised): the scariest failures aren't crashes, they're agents that repeat the same mistaken assumption across sessions with zero awareness.
The four-layer architecture you describe maps well to what I ended up building for context persistence. If overnight agent ops interest you, I wrote about the session boundary design that makes it survivable: https://thoughts.jock.pl/p/building-ai-agent-night-shifts-ep1
Brilliant and very helpful.